1. 体会异步并发的奥妙
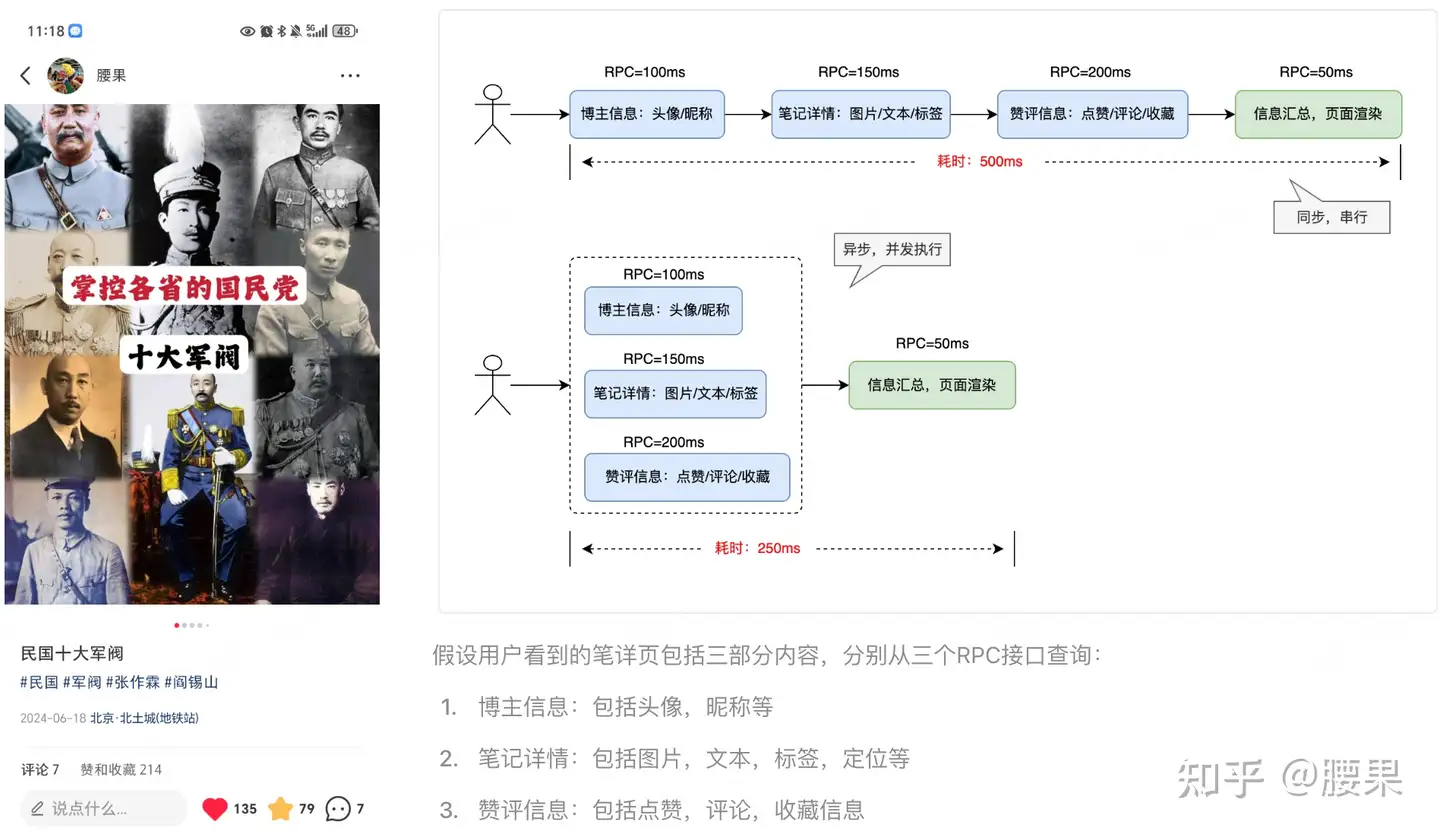
以小红书笔详页面渲染为例,抽象一个简单的业务场景:
public NoteDetail getNodeDetail(String noteId) {
Futrue<UserInfo> userFuture = threadPool.submit(() -> queryUserInfo(noteId));
Futrue<NoteInfo> noteFuture = threadPool.submit(() -> queryNoteInfo(noteId));
Futrue<CommentInfo> commentFuture = threadPool.submit(() -> queryCommentInfo(noteId));
NodeDetail noteDeital = NoteDetail.build();
try {
UserInfo userInfo = userFuture.get(1L, TimeUnit.SECONDS);
NoteInfo noteInfo = noteFuture.get(1L, TimeUnit.SECONDS);
CommentInfo commentInfo = commentFuture.get(1L, TimeUnit.SECONDS);
noteDetail.userInfo(userInfo).noteInfo(noteInfo).commentInfo(commentInfo).build();
} catch (Exception e) {
log.error("get note detail error, noteId:{}", noteId, e)
}
return noteDetail;
}思考:
1. 这种写法还有优化的空间吗?或者它还有哪些不足?
2. 你用过CompletableFuture吗?日常开发中是怎么用的?
public NoteDetail getNodeDetail(String noteId) {
CompletableFuture<UserInfo> userFuture = CompletableFuture.supplyAsync(() -> queryUserInfo(noteId), threadPool);
CompletableFuture<NoteInfo> noteFuture = CompletableFuture.supplyAsync(() -> queryNoteInfo(noteId), threadPool);
CompletableFuture<CommentInfo> commentFuture = CompletableFuture.supplyAsync(() -> queryCommentInfo(noteId), threadPool);
return CompletableFuture.allOf(userFuture, noteFuture, commentFuture)
.thenApply(v -> buildNoteDetail(userFuture.join, noteFuture.join, commentFuture.join))
.exceptionally(ex -> {
log.error("get note detail error, noteId:{}", noteId, ex);
return NoteDetail.build().build();
})
.completeOnTimeout(NoteDetail.build().build(), 1, TimeUnit.SECONDS)
.join();
}
private NoteDetail buildNotDetail(UserInfo user, NoteInfo note, CommentInfo comment) {
return NoteDetail.build()
.userInfo(user)
.noteInfo(note)
.commentInfo(comment)
.build()
}2. 为什么是CompletableFuture
2.1 Future的局限
a. 获取结果的方式不够友好
无法主动通知/监听结果,只能通过 get() 或 isDone() 主动查询,不能自动回调通知。get()是阻塞调用,在子线程获取结果之前,主线程会一直等在那里,这与Future的初衷——异步编程思想相违背;isDone()是通过不停轮询的方式获取结果,这会使CPU空转,浪费大量资源。
Future<String> future = executor.submit(() -> "Result");
// 同步阻塞等待
String result = future.get();
System.out.println(result);
// 非阻塞回调
CompletableFuture.supplyAsync(() -> "Result").thenAccept(result -> System.out.println("Callback: " + result)); b. 不支持链式调用和任务组合
对于一些复杂的任务关系不支持链式调用和任务组合,全靠手动实现,代码冗余,不利于维护和理解,比如:
1)A -> B -> C的场景
// 任务1:获取用户ID
Future<Integer> userIdFuture = executor.submit(() -> 1001);
// 阻塞等待第一个任务完成
Integer userId = userIdFuture.get();
// 任务2:根据ID查询用户名
Future<String> userNameFuture = executor.submit(() -> "User-" + userId);
// 再次阻塞
String userName = userNameFuture.get();
System.out.println(userName); // 输出:User-1001
// 无需阻塞等待,自动串联任务
CompletableFuture.supplyAsync(() -> 1001).thenApplyAsync(userId -> "User-" + userId).thenAcceptAsync(System.out::println);2)A + B -> C的场景
Future<Integer> future1 = executor.submit(() -> 10);
Future<Integer> future2 = executor.submit(() -> 20);
// 阻塞等待所有任务完成
int sum = future1.get() + future2.get();
System.out.println("Sum: " + sum); // 输出:Sum: 30
CompletableFuture<Integer> cf1 = CompletableFuture.supplyAsync(() -> 10);
CompletableFuture<Integer> cf2 = CompletableFuture.supplyAsync(() -> 20);
cf1.thenCombine(cf2, Integer::sum).thenAccept(sum -> System.out.println("Sum: " + sum));c. 异常处理不够优雅
Future需要在get()的时候主动获取异常并处理,无法在链中传递,这在流式编程风格下显得格格不入,也会导致有些写法特别冗余
Future<String> future = executor.submit(() -> {
if (true) {
throw new RuntimeException("Oops!");
}
return "Success";
});
try {
future.get(); // 异常在此处暴露
} catch (ExecutionException e) {
System.out.println("Error: " + e.getCause()); // 需解包真实异常
}
CompletableFuture.supplyAsync(() -> {
if (true) {
throw new RuntimeException("CompletableFuture Error!");
}
return "Success";
}).handle((result, ex) -> {
if (ex != null) {
return "Fallback Value"; // 提供降级结果
}
return result;
}).thenAccept(System.out::println); // 输出:Fallback Value2.2 CompletableFuture简介
a. 设计思想与原理
CompletableFuture中包含两个字段:result和stack。result用于存储当前CF的结果,stack(Completion)表示当前CF完成后需要触发的依赖动作(Dependency Actions),去触发依赖它的CF的计算,依赖动作可以有多个(表示有多个依赖它的CF),以栈的形式存储,stack表示栈顶元素。这种方式类似“观察者模式”,依赖动作(Dependency Action)都封装在一个单独Completion子类中。
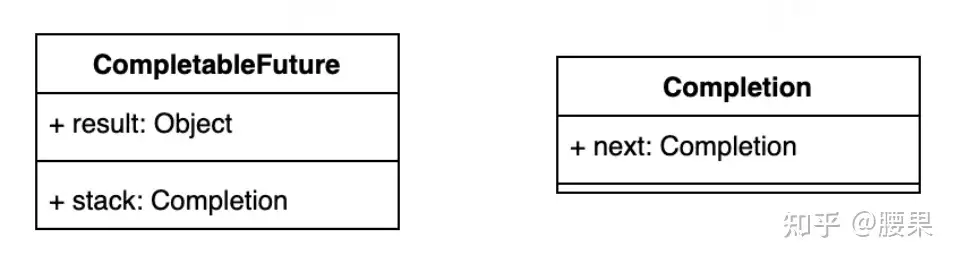
按照类似“观察者模式”的设计思想,原理分析可以从“观察者”和“被观察者”两个方面着手:
被观察者:即当前正在执行的CompletableFuture
其内部有一个Completion类型的链表成员变量stack,用来存储注册到其中的所有观察者。当被观察者执行完成后会弹栈stack属性,依次通知注册到其中的观察者。
被观察者CF中的result属性,用来存储返回结果数据。这里可能是一次RPC调用的返回值,也可能是任意对象。
观察者:可以认为就是回调逻辑,即当前CompletableFuture执行完要去做的事,可以是多个CompletableFuture支持很多回调方法,例如thenAccept、thenApply、exceptionally等,这些方法接收一个函数类型的参数f,生成一个Completion类型的对象(即观察者),并将入参函数f赋值给Completion的成员变量fn,然后检查当前CF是否已处于完成状态(即result != null),如果已完成直接触发fn,否则将观察者Completion加入到CF的观察者链stack中,再次尝试触发,如果被观察者未执行完则其执行完毕之后通知触发。
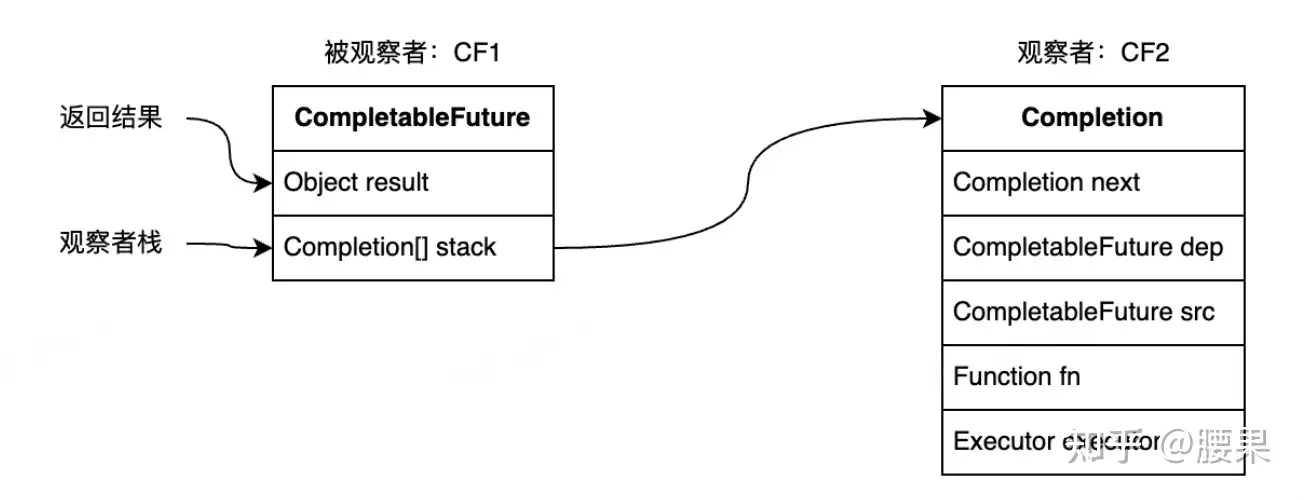
观察者中的dep属性:指向其对应的CompletableFuture,在上面的例子中dep指向CF2。
观察者中的src属性:指向其依赖的CompletableFuture,在上面的例子中src指向CF1。
观察者Completion中的fn属性:用来存储具体的等待被回调的函数。
b. 实战:响应式编程
背景:部门最近在做服务架构升级,要从响应式升级为分层架构,大概流程如下:
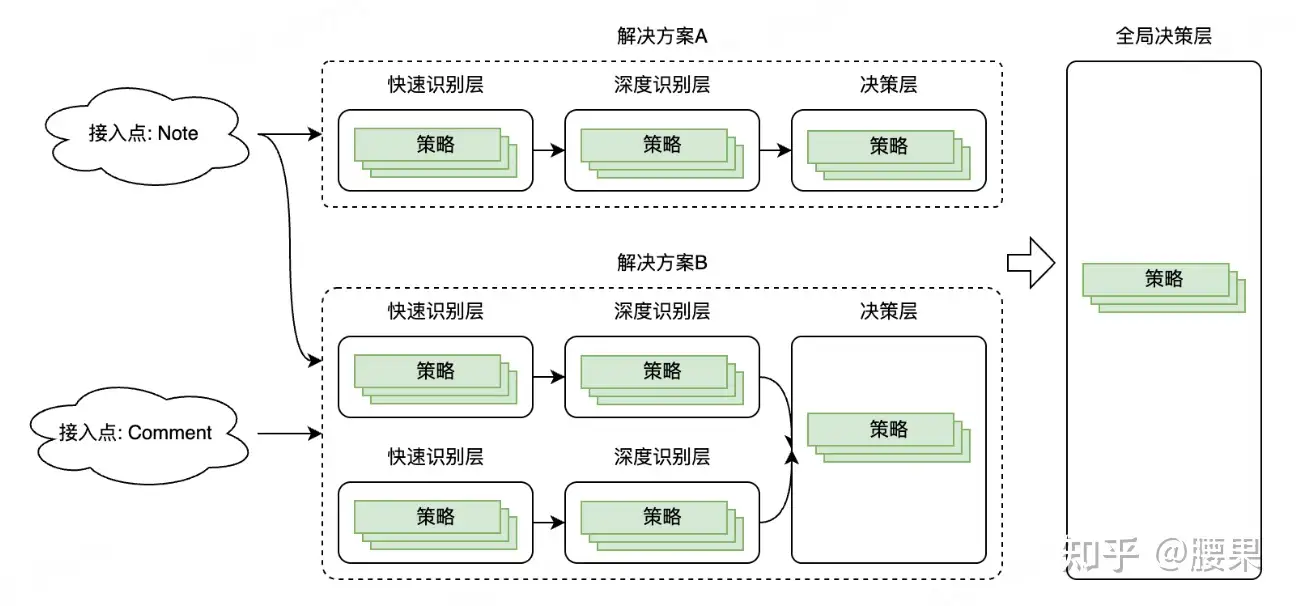
层与层之间是串行的,不同层之间一定会有策略依赖相同的外部数据,如果不做“去重”处理,会导致调下游服务QPS增加,而且可能是翻倍的增加,所以我们需要这样一种能力:在同一条请求中,多层中的相同的外部数据能够相互复用,只调一次下游就行。
思考:如果是你,会怎么做?
ConcurrentHashMap<String, CompletableFuture<String>> cacheMap = new ConcurrentHashMap();
public void asyncQueryRpcFactors() {
List<String> factors = Arrays.asList("factor1", "factor2", "factor1", "factor3");
factors.forEach(factor -> {
// 复用future,只有第一次会发起实际调用
CompletableFuture<String> future = cacheMap.computeIfAbsent(
factor,
k -> CompletableFuture.supplyAsync(() -> invokerAsync(k))
);
// 所有回调注册都OK
future.thenAccept(data -> doBusiness(factor, data));
});
// 等待所有异步结束,仅为演示
cacheMap.values().forEach(f -> {
try {
f.get(1, TimeUnit.SECONDS);
} catch (Exception ignored) {
}
});
}
private String invokerAsync(String factorId) {
System.out.println("invoke=" + factorId);
// 模拟异步调用返回值
return "mockValue-" + factorId;
}
private void doBusiness(String factorId, String value) {
// 模拟处理业务逻辑
System.out.println("Processing business for " + factorId + " with value: " + value);
}3. 总结回顾
回顾一下,到底什么是CompletableFuture?或者说它有什么特点?适合在什么场景中使用?我总结了关于CompletableFuture的几个关键字:
异步回调:不用傻傻的轮询或者同步阻塞获取异步结果,可以把回调逻辑注册进去,”响应式“执行,实现真正的异步!
链式组合:通过CompletableFuture丰富的API可以实现各种各样的Task组合,且能够跟流式编程,Lambda表达式无缝衔接。
优雅简洁:代码简洁,便于理解,比如优雅处理异常。
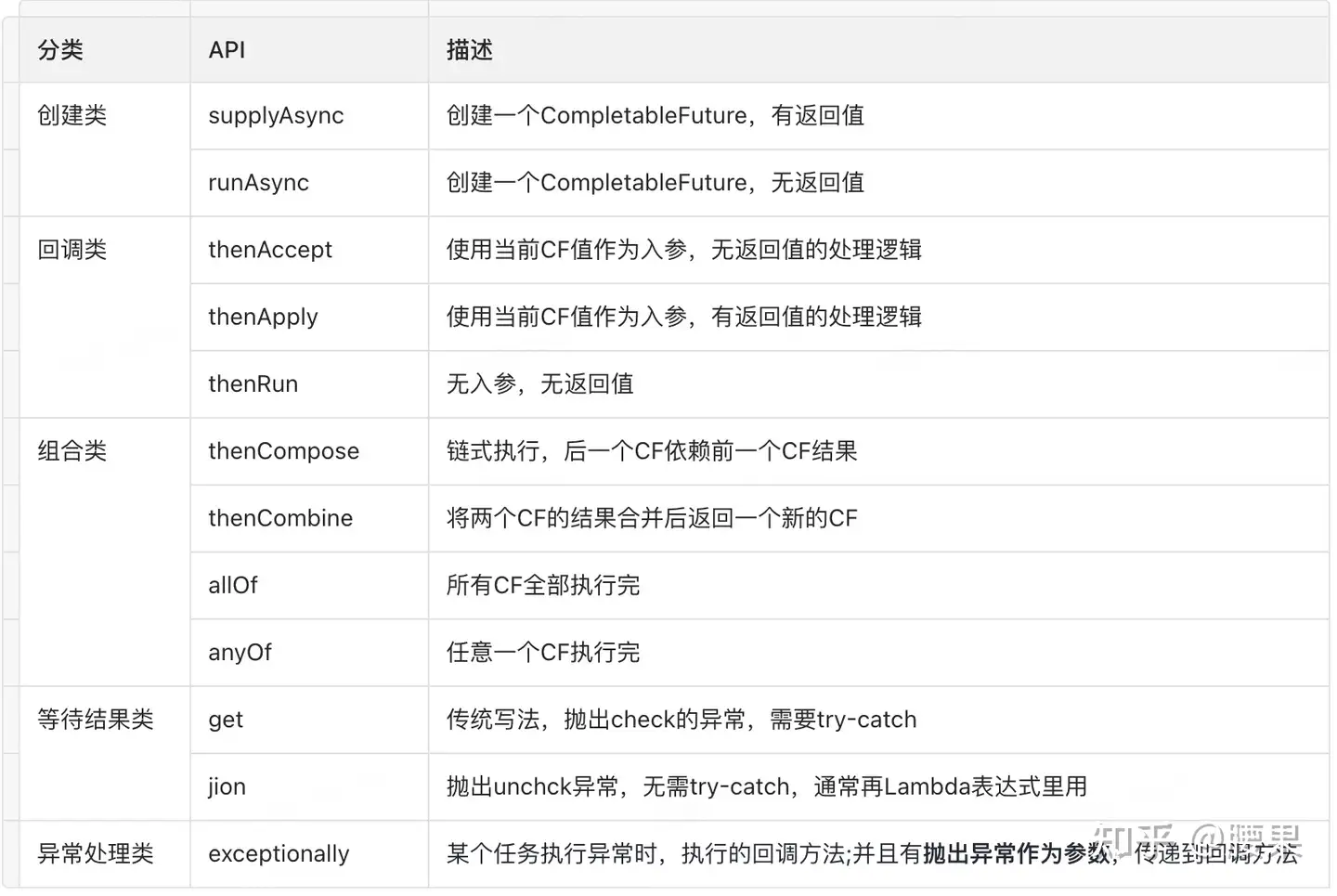
附1-CompletableFuture常用API
附2-关于CompletableFuture线程池的注意事项
上面提到的API接口都有可以传自定义线程池方法,这里强烈建议传自己定义的线程池,且根据实际情况做线程池隔离。当不传递线程池时,会使用ForkJoinPool中的公共线程池CommonPool,这里所有调用将共用该线程池,核心线程数=处理器数量-1(单核核心线程数为1),所有异步回调都会共用该CommonPool,核心与非核心业务都竞争同一个池中的线程,很容易成为系统瓶颈。手动传递线程池参数可以更方便的调节参数,并且可以给不同的业务分配不同的线程池,以求资源隔离,减少不同业务之间的相互干扰。
